エス・エー・エス株式会社では一緒に働く仲間を募集しています
社内データを活用したチャットボット(社内検索基盤)を作ってみる(Amazon Bedrock+ Amazon Kendraで作るAIサーチ&チャットシステム)

on 2024/03/29
こんにちは!
エス・エー・エス株式会社の海田です。
今年の花粉症が(個人的には)それほど酷くなくてホッとした3月でしたが、皆様はいかがお過ごしでしょうか。私は最近なぜか読書にはまってしまい、今月だけで10冊くらい読みました。
内容としては宇宙、量子力学や哲学など、普段のお仕事とはあまり関係ないものが多いのですが、このような分野を知ると、「認識」「存在」「限界」といった言葉の意味についてとても刺激を受けるので面白いです。また、宇宙の壮大なスケールの中では「粒にも満たない存在」として自分がいるという感覚が面白くなってきて、小さなことがどうでもよくなります(笑)
またゲームは最近Steamで安くなっていたモンハンワールドをやり始めました。(下手だけど双剣楽しい!)モンハン20周年らしいですね、おめでとうございます!
1. Amazon Bedrock
さて、今月は何を書こうかなと考えていたところ、面白そうなワークショップを見つけました。
「生成AI体験ワークショップ」
https://catalog.workshops.aws/generative-ai-use-cases-jp/ja-JP
(説明抜粋)
このワークショップでは、Generative AI (生成 AI) を活用したアプリケーションを
AWS 上に構築し、社内データを活用したチャットボットや要約、文章校正、画像生成などの
ユースケースを体験していきます。Amazonでも生成AIサービスは登場していて、「Amazon Bedrock」というのがその主軸になります。Bedrockとは基盤モデル(生成AIを利用するための基盤エンジン)を選択し、利用するユーザーへの統一的なAPIインタフェースを提供するサービスです。つまり、AWSの各種サービスとBedrockを組み合わせて、ChatGPTやStableDiffusionのような機能を実現できます。このワークショップではそれらを構築するところから始めて、実際に機能を体験できます。
私はAmazon Bedrockというサービスがあったことは知っていたのですが、実際利用したことがなかったので、いい機会だなと思い試してみることにしました。これが思いのほか面白く、DXと言われている昨今にまさしくこれじゃないか!と思えるような内容でしたので記事にすることにしました。
2.構築してみる(30分でできたよ!)
では構成図を見てみます。
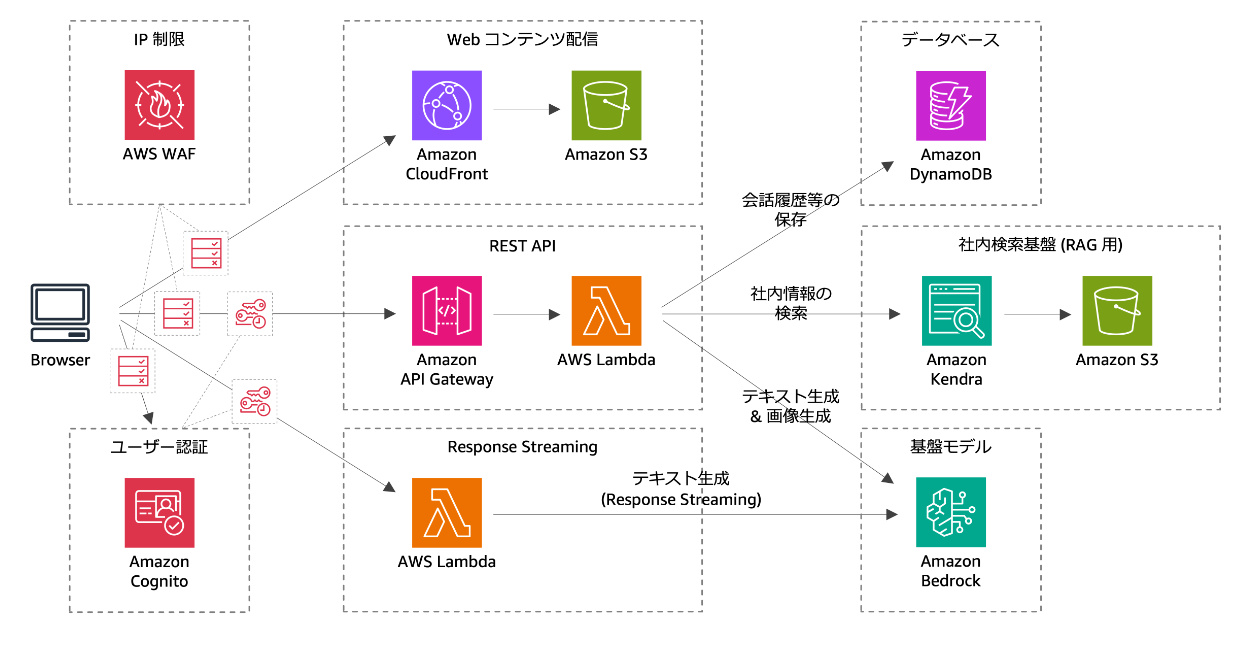
すべてサーバレスで構築されています。
- Webコンテンツ配信にCloudFrontとS3
- ユーザ認証にはCognito
- 社内検索基盤(RAG)にはkendraとS3
- 基盤モデルにはBedrock
- Bedrockへの問い合わせ処理にはAPI-GatewayとLambda
- 履歴保存にはDynamoDB
- セキュリティにはWAF
いきなりたくさんのAWS用語が出てきて混乱してしまうかもしれませんが、沢山のサービスが組み合わさって構築されているということを理解していただけるだけで大丈夫です。ちなみにこれを全て構築するのにどれくらいの時間がかかると思いますか?
私の実体験ですが、たった30分で構築可能でした!
コマンドを1行叩けば上記のサービスが全て構築されます!!(後述する通りコマンドを叩くまでの諸々の準備はありますがそれらを含めて30分でできました)
この高速構築を可能にしているのが「AWS CDK」というサービスです。AWSが提供するインフラ自動構築(IaC)サービスとして有名なのは「CloudFormation」ですが、CDKはその上位互換的なものです。より簡単に柔軟にAWSサービスの自動構築とバージョン管理をサポートしてくれます。
上記の構成図の通り、単純なWEBコンテンツとしてだけではなく、セキュリティやユーザの認証認可サービスも包含されているので、内部で使う分にはほぼこれだけで十分な気がします。
このワークショップの素晴らしいところは、これだけの機能が入っているにもかかわらずAWSアカウントさえあればだれでも簡単に実践できるようになっているということです。後片付けの方法も書かれているのでコスト面でも安心です。
大まかな流れだけ列挙します。たったの3ステップです。
- 1.バージニア北部リージョンでBedrockが利用する基盤モデルを有効化(5分)
- 2.東京リージョンでCloudshellを立ち上げてコマンド叩いてCloud9を起動(5分)
- 3.立ち上げたCloud9でGit資産DL&自動構築コマンド実行(20分)
最後の実行でアクセスするURL(https://xxxxxx.cloudfront.net)が出てくるので、それをブラウザで入力すればアクセスできるようになります。必要に応じて接続元IPを制限する方法(WAF設定)も書かれています。(親切ですね!) またCloudfront用意のデフォルトURLを利用しているので、特別な考慮不要で通信が暗号化(HTTPS接続)されています。(素晴らしいですね!)

サービス構築できたら実際に使ってみましょう。メールベースのログイン認証システムが既に出来上がっているので、「アカウントを作る」から新規ユーザ登録をしてログインします。ちなみにパスワードは大文字小文字、特殊文字を含む8文字以上だったかな・・そこそこ強めです。登録したメアドに認証コードが届くので、それを入力すればログインできます。

3.利用してみる
さて、Web画面を見てみましょう。とてもサンプルとは思えないくらいクオリティが高いです。そのままオレンジ枠の「デモ」を押下してもいいですし、左側のメニューから選んでもいいです。

基本はChatGPTと同じように利用できますが、面白いと思った機能を何点か挙げます。
3-1.文書生成機能
日程調整メールの返事やクレームメールへの謝罪返信などをユースケースとして挙げています。例えば、お客様からの提案メールで日程を回答したい場合、以下のように「受信したメール本文」と「期待する生成条件」を入力して実行ボタンを押下します。(今回であれば、頂いたメールに「返信するメール」を生成してほしい、かつその本文に日時を指定して回答するように依頼しています)

そうすると以下のような返信メールを自動で作成してくれます。命令の条件によっても変わりますし、同じ命令でも何パターンか用意してくれます。

3-2.Webコンテンツ抽出機能
WEBページを要約してくれる機能です。WEBで公開されているマニュアルや記事を簡潔に要約してくれるので利用の機会は多いかと思います。例えば前回のTechBlog記事「Googleの生成AI「Gemini」を試してみる」のリンクを入れて抽出させてみると以下のように出力されます。結構いいですよね!

他にも翻訳や画像生成、音声認識などの機能があります。このような各種機能が一つのWebポータルとしてまとまっているのは、非常に使いやすいですね。繰り返しですが、これがたったの30分で構築できるというのがすごいことだと思います。(長々と要件定義をしている間に実行環境が出来上がってしまうのです)
しかし私が本当にすごいと思っているのは次の技術(RAG)です。
4.RAGとは・・
さて、本日最もお話ししたい内容に移ります。いきなりRAGという単語を出してしまいましたが、この言葉の説明の前に、まずは事例を・・
ーーーーー事例ここからーーーーー
ある架空の会社はたくさんの従業員がいて、システムや会社の制度に関する問い合わせが殺到します。
「社内のWI-FI設定方法とパスワードって何だっけ?」
「社内でこういう規則あったっけ?」
「出張費用を申請したいんだけどどうすればいいんだっけ?」
「2023年度の会社の売り上げ実績は?」
・・・・
それぞれの手順書やドキュメントはあるのですが、それらは全体的に散らばっていて、探すのが面倒でした。なのでこの会社ではこのような怒涛の問い合わせを、都度都度担当者が答えています。担当者の負荷は増し、簡単に休むことすら難しい状況です。また質問する社員の方々も回答のレスポンスが悪くて不満感が強いです。会社としてはこの状況を何とかしたいと考えています。
ーーーーー事例ここまでーーーーー
さてこれをどうすればよいでしょうか?とあるコンサルに相談したところ、そのコンサルは答えました。
・問い合わせに対応するドキュメントが既にあるのであれば、それをシステムが自動的に探して答えられるようにすればよいのではないか?
素晴らしい解決策だと思います。担当者の負荷も減りますし、問い合わせる側も気兼ねなく聞けて迅速な回答が得られますね。しかし、そのためには2つの条件が必要です。
- 1.格納された膨大な資料から、的確で迅速な検索が出来ること(エンタープライズ検索)
- 2.ユーザの質問や検索結果の意図を柔軟にくみ取り、的確に文書生成して応答すること(生成AIの文章生成)
この2つの条件を組み合わせる手法をRAG(Retrieval Augmented Generation)と言うようです。
このワークショップでは1.の実現のためにエンタープライズ検索エンジンである「Amazon kendra」を、2.の実現のために「Amazon Bedrock(と選択した基盤モデル)」を採用して、RAGを実現しています。下の図のピンクで囲った部分ですね。
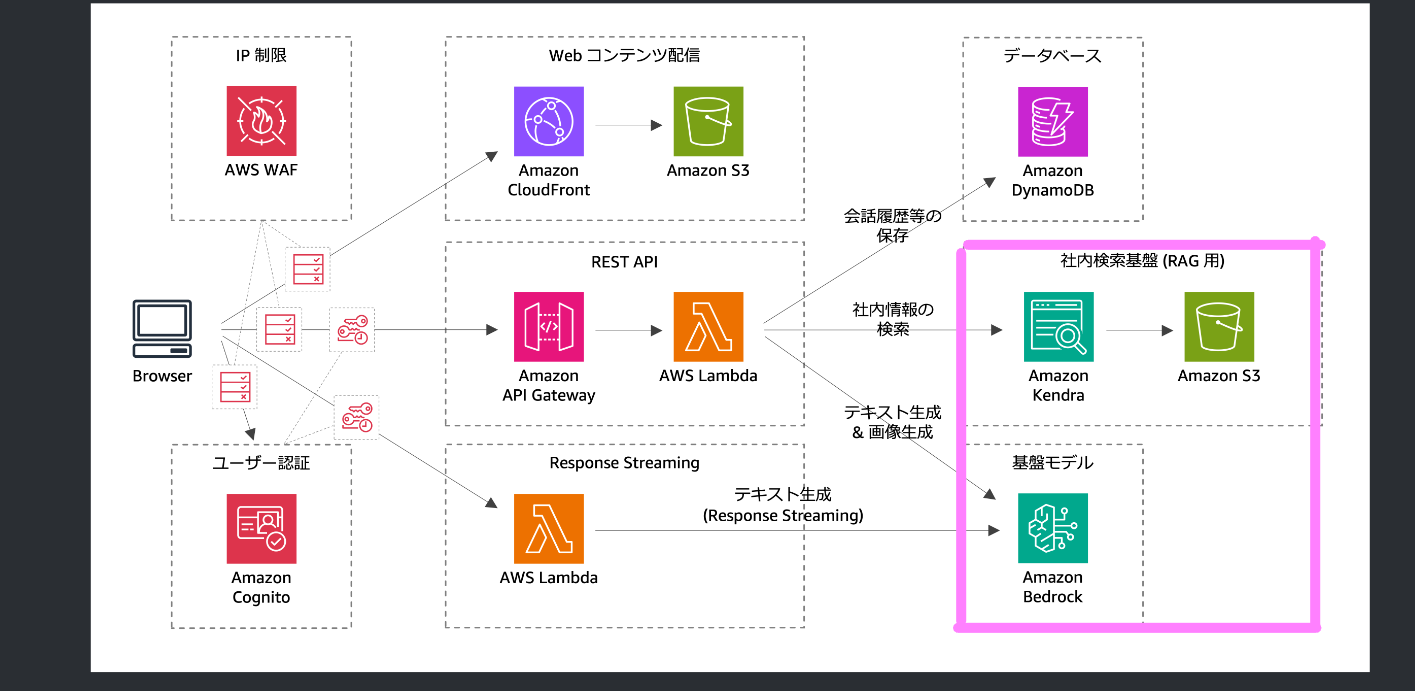
そしてこのワークショップではKendraとBedrockを組み合わせたRAGを気軽に試すことができます。これはどういうことかというと「社内検索基盤(社内データのAIサーチ&チャットシステム)を超簡単に実現できてしまう」ということです!
社内の必要なドキュメントを全て一か所にまとめ、その内容に関してチャットするとAIが高速検索して的確な回答を返してくれるということです。
具体的には、以下のような流れです。
- 1.RAG機能を有効にして再デプロイ
- 2.ドキュメント類をS3にアップロード
- 3.KendraとS3の連携
ワークショップの実際の事例では、社内規定を書いたサンプルドキュメントをアップロードして、それに対応した質問をしています。事例の通り、ソース情報(どのドキュメントのどの場所に書いてあったのか)も記載してくれます。
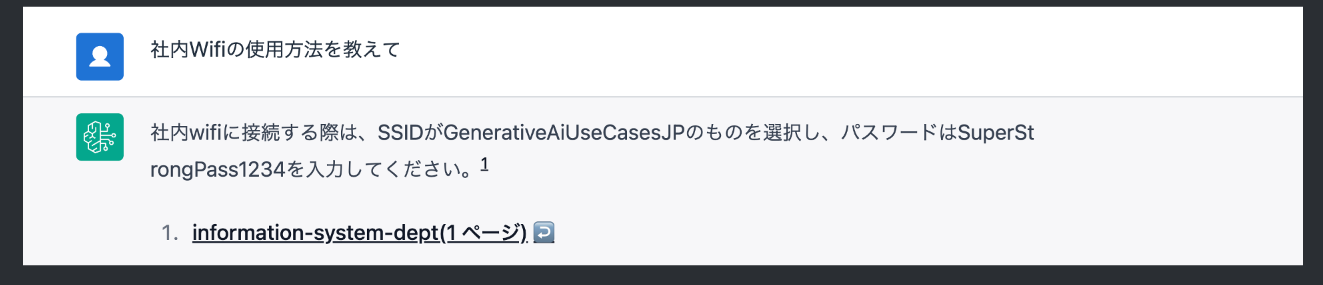
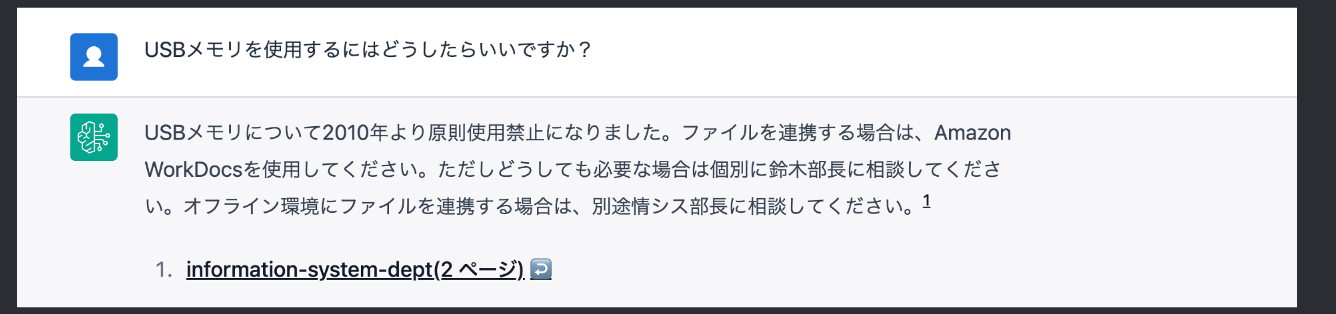
人を介さずに問題が解決するのはとてもいいですね。
私も自身の楽器(シンセサイザー)のマニュアルなんかも格納してみて、その機能を試してみました。得手不得手はあるようですが、基本的にテキストドキュメントであればほぼ正確な回答かなと感じました。RAGを採用することで頑張って作った手順書やドキュメントが読んでもらえずに質問される・・という嘆きも減りそうですし、いずれこのような仕組みを浸透させる方向にシフトするのであれば、RAGに対応した的確なドキュメントを作成していくという意欲にもつながりそうですね。
なお今回、KendraはS3と連携しましたが、他にもデータソースとしてSharepointやGoogleDriveなどとも連携できるようです。利用者が多そうなこれらのデータソースと連携させればそれだけでAI検索、回答生成の恩恵を受けられるというのはすごいことだと思います。
5.まとめ
生成AI体験ワークショップおよび「Amazon Bedrock+ Amazon Kendra」で作る社内検索基盤の概要を記載してきました。いかがでしたでしょうか?個人的には即実用レベルとなるような体験ワークショップだなと感じました。もちろんCloudfrontのURLを独自ドメインに変えるとか、WAFのIPやシグネチャ設定、管理者によるユーザ管理、ログ管理など、要件に応じてカスタマイズ必要な部分もあるかとは思いますが、社内の少人数で使う分には十分な気がしました。
なによりRAGによる社内検索基盤の実現は、社内の既存の事務作業改善に絶大な効果を発揮するのではないかという可能性を感じましたし、社内だけにとどまらず、プロジェクトを進める上でのよく問題となる「どこに書いてあるかわからない」とか「引継ぎにすごく時間がかかる」といった事象も解決する可能性を秘めているのではと思いました。個人の備忘録格納としても役立ちそうですよね。
個人的には(文面の体裁とか規定とか社内慣習とか余計なことを気にせずに)RAG利用を前提としたドキュメント作成に意識を集中できるというのが一番の継続的メリットのような気がします。
じゃあ、デメリットはないの?ということなのですが、唯一のデメリットは値段・・ですかね。無料期間もありますが、継続的に利用していくとなるとある程度のコスト(特にKendra)がかかります。しかし、わずか30分で構築でき、運用後の管理工数も減るということであればトータルで考えれば全然お安いのかもしれません・・。
一応、私が作ったものも社内向けに公開する予定です!(ほぼワークショップそのままだけど(笑))
個人や会社の検証用のAWSアカウントをお持ちであればぜひお試しください!
最後までお読み頂きありがとうございました!
社内データを活用したチャットボット(社内検索基盤)を作ってみる(Amazon Bedrock+ Amazon Kendraで作るAIサーチ&チャットシステム)

/assets/images/4011356/original/888630f0-8d41-4054-8de3-5be6c86f98d7?1566135134)




/assets/images/11403610/original/888630f0-8d41-4054-8de3-5be6c86f98d7?1670285641)